I few weeks ago, I described an integration I built to pull data from the Stripe via its API and load it into BigQuery. There were two main problems with this approach: First, it was incredibly hacky – a Wile E. Coyote approach to the problem involving cron jobs and EC2 instances and GCS uploads and scheduled jobs in BigQuery. It got the job done, but in a way that was slightly embarrassing. Second, everything else we did was leveraging FME and this stood outside of that pattern.
I really wanted to bring this process into the FME fold, but I needed to tackle Stripe’s API pagination in order to do it. Most of Stripe’s helper libraries have an auto-pagination feature that allows you to keep loading objects until you reach the end. This feature is not available if you are using the raw Stripe REST API, which is essentially all that is available to FME via the HTTPCaller transformer.
Stripe’s API uses cursor-based pagination, meaning that it points to the ID of the next object to read in the dataset. Luckily, Safe Software has an article that describes how to handle cursor-based pagination. This article is that it uses the Slack API as an example. The Slack API is well designed and returns everything you need to handle pagination in one place in the response document, but this isn’t the case with Stripe’s API so I had to modify the approach somewhat.
In the case of Stripe, a response that lists objects will include a property called “has_more” which will be true or false. If true, you need to parse the main body of the response document to get the ID of the last object in the list so you can use that in the subsequent call to fetch the page “before” or “after” (more on that later). This added a little bit of a wrinkle to the process, but wasn’t too strenuous.
In the Stripe API response, the list of objects returned is in a property called “data”, which resides at the same level in the document hierarchy as the “has_more” property mentioned above. So I started by using a JSONExtractor to pull those two properties out into attributes. As shown here.
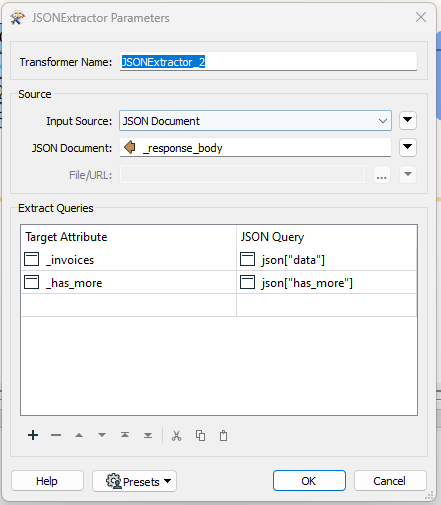
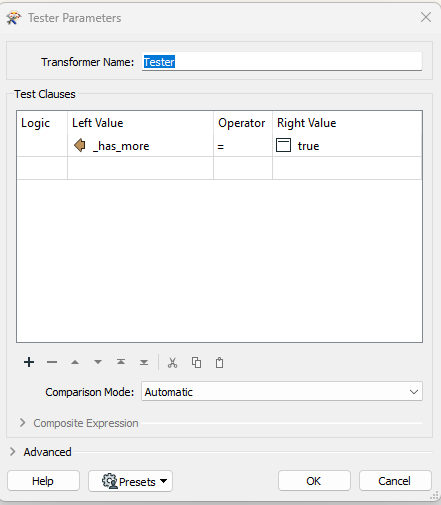
The next step is to use a Tester transformer to check the value of the “_has_more” attribute to see if there are additional records that need to be fetched.
Assuming that there are additional pages to be fetched, the next step is to parse the “_invoices” attribute to extract the object ID that triggers the next page. Here, I needed to extract the ID of the first object in the list and capture that into an attribute called “_starting_after”.
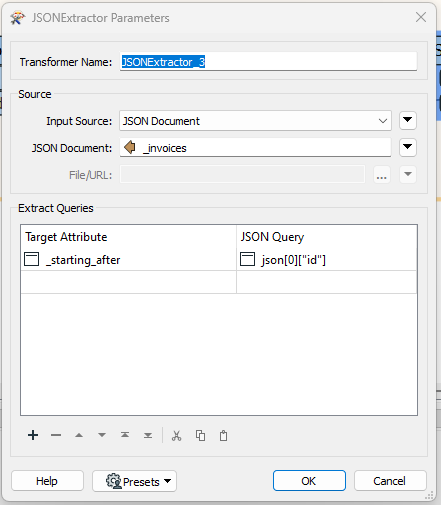
This was somewhat unintuitive because Stripe returns objects in reverse chronological order, so that the new object is the first in the list and the oldest in the last in the list. The Stripe API uses parameters called “starting_after” and “ending_before” to navigate pagination. Each of these expects an object ID, but they reference the data temporally. The means that “starting_after” requests records created after the one with the ID provided, rather than those that would appear after it in any arbitrarily-sorted list. This why I set the “starting_after” parameter with the ID of the first item in the list (the newest) rather than using the “ending_before” parameter.
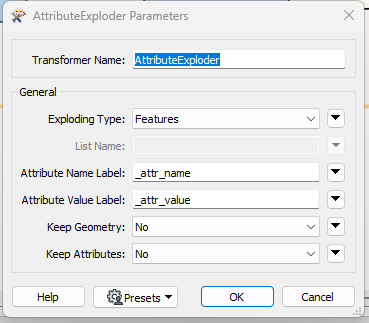
Up to this point in the process, I’ve had two attributes moving along together: _invoices and _has_more. Now that I know that I have more pages to process and where to set the cursor for the next page, I can split these attributes up for their respective processing. This involves two steps. The first step requires the use of an AttributeExploder transformer to get the data into a standardized name-value pair structure.
Once this is done, then I use a TestFilter transformer to route the data based on the attribute name.
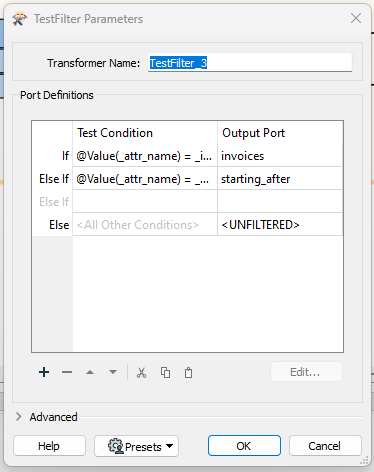
As can be seen, this transformer encapsulates an IF statement that simply routes data to different output ports based on the attribute name. This has the effect of branching the process.
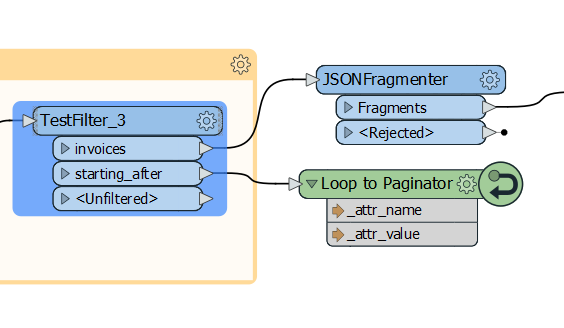
The TestFilter routes the invoices on for further processing to eventually be written to output. The “starting_after” parameter is passed back through a transformer loop to a transformer input which will fetch the next page and keep the process going until all pages have been handled.
Using this approach, I was able to move this process into FME along with our other data-handling routines and sunset the original, cron-based approach. This is another example of how FME provides the necessary tools to perform fine-grained ETL of non-spatial data,