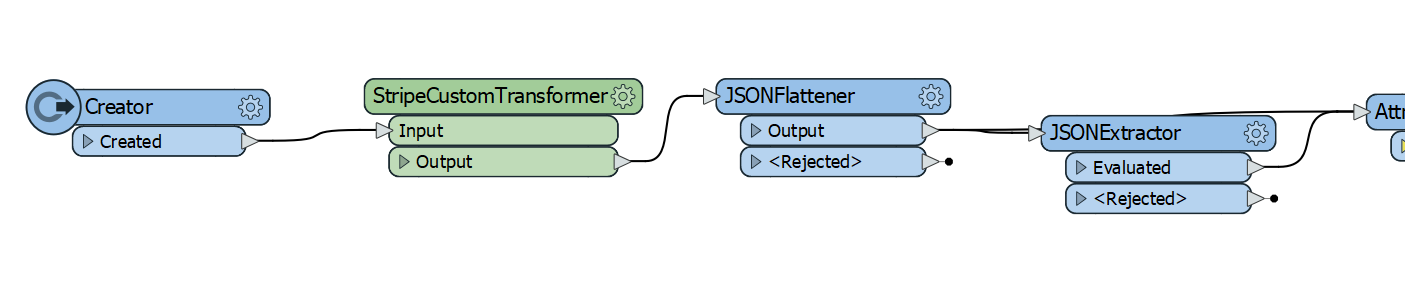
I few weeks ago, I described an integration I built to pull data from the Stripe via its API and load it into BigQuery. There were two main problems with this approach: First, it was incredibly hacky - a Wile E. Coyote approach to the problem involving cron jobs and EC2 instances and GCS uploads … Continue reading Stripe API Pagination in FME
Stripe API Pagination in FME