It’s been a few months since I’ve posted, owing mainly to getting my feet under me at Spatial Networks. About a month after I started, the company re-merged with Fulcrum, which had previously been spun off as a separate company. As a result, I’ve gotten to know the Fulcrum engineering team and have gotten to peer under the hood of the product.
Of course, Spatial Networks is also a data company. What had originally attracted me was the opportunity to help streamline the delivery of their data products, and this remains a pressing issue. This has kept me elbow-deep in PostGIS, and has led me to delve into using materialized views more than I have before.
What is a materialized view? If you are familiar with relational databases, then you are familiar with views, which are saved queries that are stored in the database. Similar to tables, you can select data from a view; but, rather than directly selecting physically stored data, you are executing the SQL that defines the view, which will stitch together data at the time of execution.
A materialized view is a useful hybrid of a table and a view. It is technically a table, because it is physically stored on disk, but it is generated from a SQL statement like a view. This is can be useful for increasing performance because costly joins and functions (ahem, spatial) are not executed every time the data is accessed. The source SQL is executed and the result written to disk. As a result, the data can be indexed and queries can executed quickly. It could be reasonably thought of as a more streamlined SELECT INTO.
So why use materialized views? If properly designed, a relational database (spatial or otherwise) is built using normalization to optimize storage, reduce data redundancy, provide constraints and enhance data quality. This is excellent for storage, but not always ideal for analytics, which is why views exist.
A materialized view provides the ability to prepare a persisted version of data that is better suited for analysis and/or human readability. In a spatial database such as PostGIS, it also provides the ability to pre-process spatial analysis to enhance database and application performance. That is what got me interested in them.
From here, it’s probably best to discuss materialized views in terms of a scenario. I’ll discuss a fairly straightforward example, data binning, which touches upon the advantages of materialized views for me.
I’ll work with four data sets:
- An extract of cellular towers from the FCC downloaded from ArcGIS Online
- US counties extracted from GADM
- 0.5-degree rectangular grid created in QGIS
- 0.5-degree hexagonal grid created in QGIS
I imported all the above into PostGIS.
My goal is to calculate the number of cellular tower in each grid square, hexagon, and county. I’ll use a fairly simple bit of SQL to do that.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| SELECT us_hex_grid.id, | |
| count(cellular.id) AS features | |
| FROM us_hex_grid, | |
| cellular | |
| WHERE st_contains(us_hex_grid.shape, cellular.geom) | |
| GROUP BY us_hex_grid.id; |
The SQL above generates a count of the towers that fall within each hex, as governed by the st_contains function and the GROUP BY clause. In a traditional view, this spatial query would executed every time I issued a SELECT statement against the view.
You will notice that I don’t return the hexagon geometry. I will create a second view that joins the geometry to the results of this query. I did that strictly to keep the SQL clean for this post, but it is perfectly fine to get all of the data in one step. The SQL that joins the hexagons is:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| CREATE OR REPLACE VIEW public.vw_cellular_count_geom_hex AS | |
| SELECT us_hex_grid.id, | |
| us_hex_grid.shape, | |
| vw_cellular_freq_hex.features | |
| FROM us_hex_grid | |
| LEFT JOIN vw_cellular_freq_hex ON us_hex_grid.id = vw_cellular_freq_hex.id; |
Notice the left join so that all of the hexagons are returned regardless of whether or not they contain towers. I included the full CREATE statement this time to highlight the contrast with the next example.
It’s now time to create the materialized view, which calls upon the view created in the previous step. This is the SQL to create the materialized view:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| CREATE MATERIALIZED VIEW public.mvw_cellular_count_geom_hex AS | |
| SELECT uuid_generate_v4() AS oid, | |
| vw_cellular_count_geom_hex.id, | |
| vw_cellular_count_geom_hex.shape, | |
| COALESCE(vw_cellular_count_geom_hex.features, 0::bigint)::integer AS features | |
| FROM vw_cellular_count_geom_hex | |
| WITH DATA; | |
| CREATE INDEX sidx_mvw_cellular_count_geom_hex_shape | |
| ON public.mvw_cellular_count_geom_hex | |
| USING gist | |
| (shape); |
Note the creation of the spatial index. This is important because a materialized view creates a new data set, so the data is divorced from any indices in the source data.
The SQL above physically writes the data to the database, similar to a SELECT INTO statement. Unlike that approach however, we can easily refresh the data by issuing the following command:
REFRESH MATERIALIZED VIEW mvw_cellular_count_geom_hex;
This enables a user or application to automatically updated the stored data whenever the underlying source data changes.
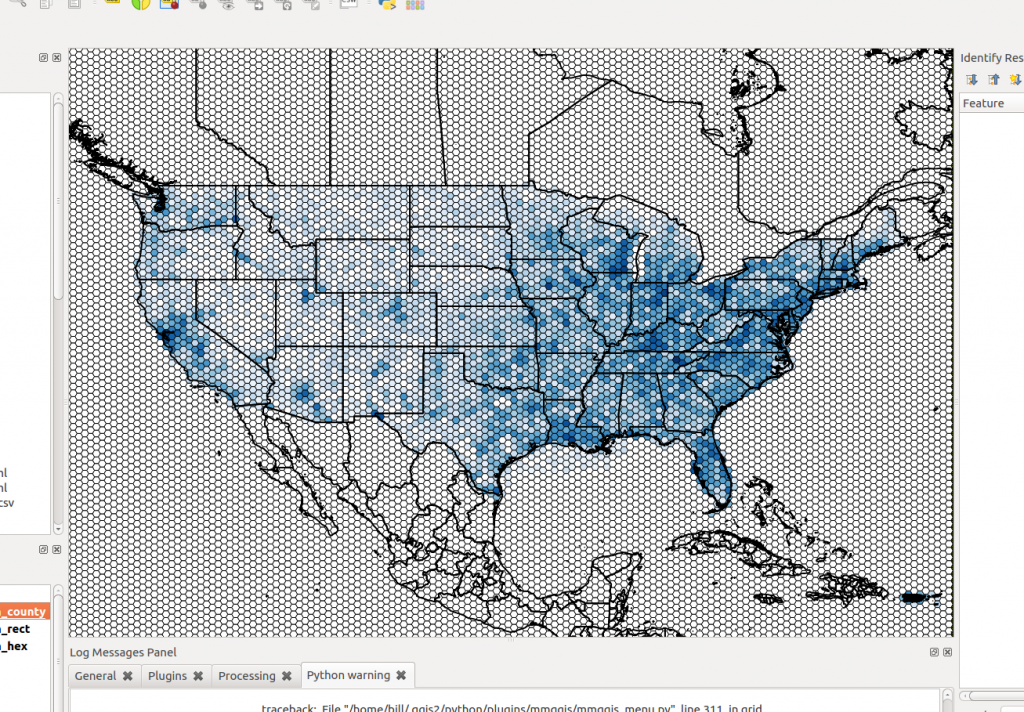
Notice in the SQL above, I am calculating a UUID column. This is being done to aid visualization in QGIS. To add a view of any kind to a QGIS map, you need to tell it what the unique identifier is for the data set. I tried numerous different approaches, but found using a UUID to work most consistently. I will keep exploring this. The binned hex grid layer (with a bit of styling) looks like this in QGIS:
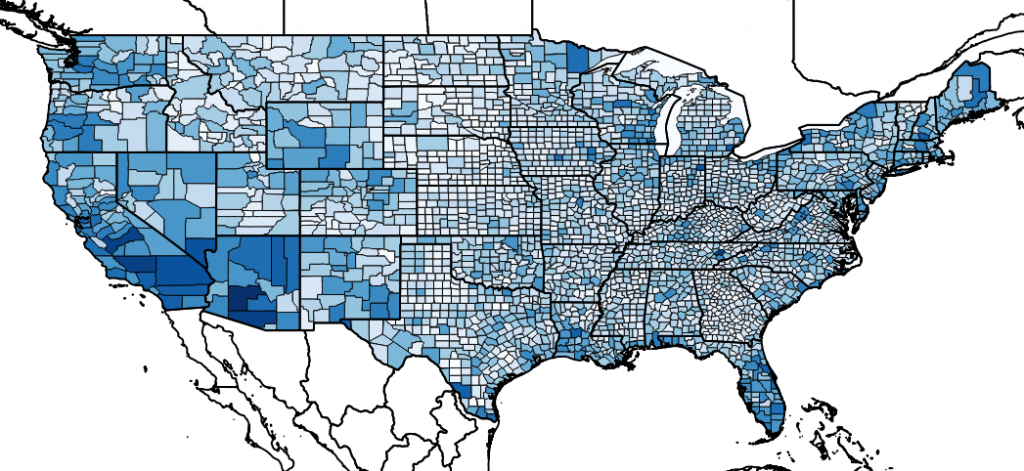
I mentioned earlier that materialized views can help performance. This really becomes apparent with complex geometries. There is minimal difference between the standard view and the materialized view when working with squares or hexes. But, to produce the county map shown at the top of this post, the standard view took 4.2 seconds to run on a Linux machine with quad-core, SSD, and 64GB of RAM. The materialized view returned in 292 milliseconds. This is where not having to re-run spatial queries using the details GADM polygons really pays off.
Materialized views are not a panacea. If you have rapidly updating data, the refresh process with probably introduce too much latency. You are also storing data, such as geometries, twice. But, depending on your needs, the benefits may outstrip the drawbacks of using materialized view in spatial applications.
This is a nice introduction to materialised views. We’ve just upgraded from Postgresql 9.2 to 9.6 and MVs have made a huge difference to performance. Slow, complex views are now lightning fast.
Thanks. I like that MVs can have their own indices and such, so you can really tune performance with them. As long as the source data doesn’t have a lot of velocity, they are a good option.
Hi Bill,
nice post about MV’s. Instead of creating UUIDs you could also use “SELECT row_number() over (ORDER BY foo) AS id” to create an identifier.
We’ve been loving MV’s … our SCHOOLS tables are made of several source tables but are built using MV’s and refreshed using Python (psycopg2) on a daily basis… we also provide data to web clients using MV’s that combine source tables for a customized version of our data just for them (that goes on through Geoserver to GeoJSON)… again refreshed daily using Python…
I like the idea of creating custom MVs for use within Geoserver – anything to make it faster!
We’re seeing good performance from MVs in GeoServer, too. They’ve quickly become a crucial part of our data pipeline.
MV’s basically replace the overhead of doing a drop and create on a table – the logic and data are contained within the MV, simply refreshing it allows the table to remain in place with all security and table schema in place… so it’s as fast as a table in terms of load times – when views take too long to load (when needed), MV’s are a great next step…