In a post last week, Open Data and AI, I discussed how open data projects are facing a new kind of consumer: AI-automated systems that can pull public data continuously, at scale, and in patterns the original infrastructure was never designed to support. OpenStreetMap is one of the clearest examples. It is globally important, community maintained, and widely reused, but it is still operated on infrastructure built around norms of shared stewardship rather than industrialized extraction.
That post posed a thought experiment about what an AI-optimized approach could look like. I decided to build a small prototype to test my assertions and to avoid identifying a problem and then walking away.
The idea is simple: if we expect AI systems to work with open geospatial data, we should give them a better pattern than repeatedly scraping live community infrastructure. Instead of pointing an agent directly at OpenStreetMap services and hoping for good behavior, we can build a local, attributable, queryable mirror from a known extract and let the AI work against that.
I built a small prototype to see how far that pattern could go with ordinary open-source components.
The Prototype
The project is an OSM AI Mirror for Maryland and Washington, DC. It takes a point-in-time OpenStreetMap extract, loads it into PostgreSQL with PostGIS and pgvector, normalizes a useful subset of tags, generates local embeddings, and exposes the result through both REST and MCP interfaces. For client-side testing of the MCP workflow, I used OpenClaw as the test client.
In practical terms, it gives an AI client a controlled way to ask questions such as:
- What coffee shops are near this point?
- What is the administrative hierarchy at this location?
- Show me places within St. Mary’s County.
- Use one geometry in the mirror, such as a county polygon or road segment, to perform spatial queries on the rest of the mirror.
The last pattern was especially useful. If the mirror already contains geometries for counties, parks, roads, and other features, the natural pattern is to let one mirrored feature become the spatial basis for querying others.
One note: the availability of OSM extracts is a big reason why I chose OSM for this work. I could pull an extract one time and do my work without spamming OSM’s infrastructure in the process.
A Possible Approach
Today, a lot of AI interaction with open data defaults to the path of least resistance. Lacking a specific MCP endpoint to use, an AI agent will exploit a live website, a tile service, a download link, or a public REST API and pull what it needs when it needs it. That works for experimentation, but it does not scale well as a social pattern. If the number of automated consumers rises sharply, it can overwhelm projects and volunteers operating shared public infrastructure that was designed for human-scale traffic.
A local, AI-optimized mirror begins to address that while also taking the first couple of steps toward a more scalable public-facing solution. Instead of repeated live access, the system downloads a bounded extract once, processes it locally, and then runs many downstream queries without touching the source again. That is friendlier to the upstream project, operationally easier, and better for reproducibility. It also gives us a place to attach the things AI systems need but raw open data often lacks: normalization, versioning, embeddings, explicit attribution, and predictable query interfaces.
The Stack
As a local prototype, the stack is intentionally straightforward.
- OSM extract: Geofabrik Maryland and DC PBF files merged into one regional snapshot
- Database: PostgreSQL 18 with PostGIS and pgvector
- Ingest: osm2pgsql flex output into a canonical osm_entities table
- Normalization: additive normalization of selected tags such as amenity, shop, tourism, historic, leisure, addresses, names, and opening hours
- Semantic embeddings: local nomic-embed-text embeddings for named normalized entities
- Geometry embeddings: deterministic multi-resolution H3-based vectors for entities with geometry
- Gateway: FastAPI REST endpoints first, then wrapped with FastMCP
A few design choices were important from the beginning:
First, raw OSM tags are preserved. The project does not overwrite source data. Normalization is additive, not destructive. Second, attribution is always carried forward. Every response includes OpenStreetMap attribution and license metadata. Third, the system is versioned and testable. Schema version, text embedding version, and geometry embedding version are recorded explicitly so downstream consumers can tell what they are looking at. Fourth, because this iteration is specifically intended as a local prototype, concepts such as caching and message queuing have been deferred to later iterations and are not addressed here.
Availability vs. Suitability
The build itself was a good reminder that “AI-ready” is not the same thing as “available online.” OpenStreetMap is accessible, but accessibility does not automatically translate into a clean machine interface for agentic use. Even with a well-structured source like OSM, there is still a lot of engineering between a raw extract and something an AI client can query reliably.
I had to solve for ingestion, normalization, geometry handling, ranking behavior, and spatial semantics. Some of the most useful work was not glamorous. For example, I fixed an ingest issue so highway ways retained line geometry correctly, which in turn made it possible to use roads as reference geometries in spatial search. That unlocked queries like “find places near Three Notch Road” using the road geometry in the mirror itself rather than a guessed point.
Hybrid AI search needs careful boundaries. For ordinary local search, true PostGIS spatial queries often make more sense than letting geometry-vector similarity influence ranking. In other words, if someone asks for coffee shops near Leonardtown, Maryland, the system should primarily behave like a spatial application with semantic help, not like a vector demo looking for excuses to be clever.
That distinction became clearer as the prototype matured. The approach was:
- use PostGIS for actual geographic relationships
- use text embeddings for semantic matching
- use geometry embeddings for specialized similarity tasks, not as a replacement for spatial SQL
That feels like a more intuitive approach for geospatial AI than flattening every problem into vector search.
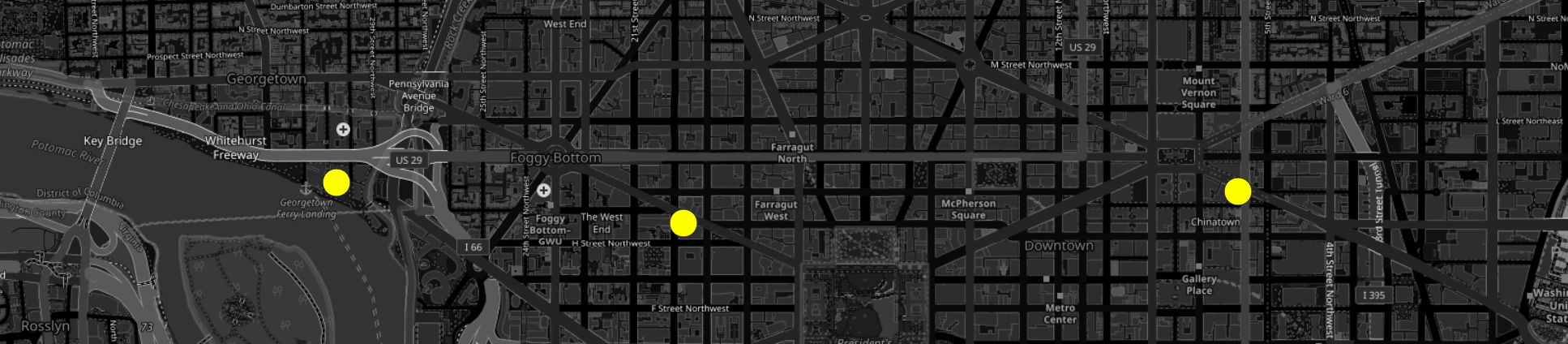
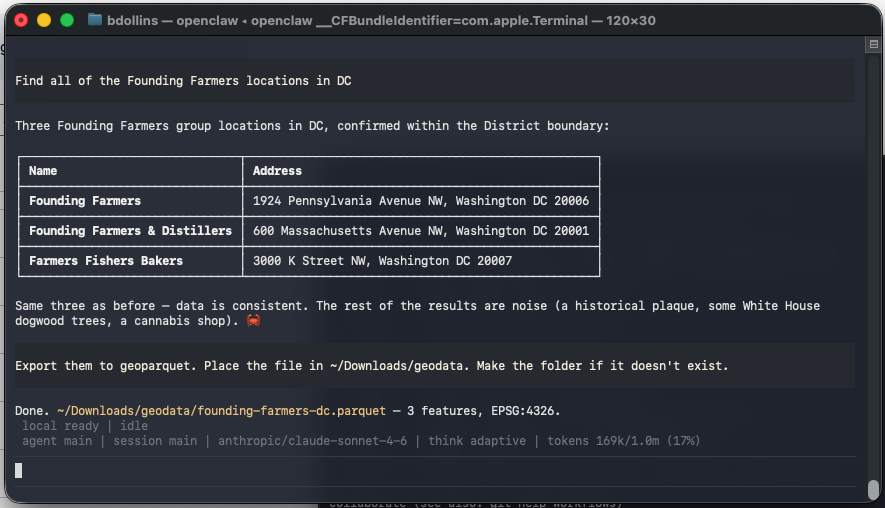
I did most of my testing in the semi-rural region where I live, because such areas often get fewer passes in OSM and can have more anomalies. After a couple of iterations, I did a query with a data-rich urban case and asked the mirror for all of the Founding Farmers locations in Washington, DC. I verified that it could identify the matching places cleanly in a dense environment, and then exported the result set to GeoParquet for downstream use.
That is a small example, but it captures the larger point of the project. It’s not just a search demo, but would be a part of a workflow that contains open geospatial data, AI-assisted querying, and analysis-ready outputs. I’ve run a few scheduled tasks in Claude Cowork and verified that it performs well with light spatial ETL. I’m not certain it’s ready to replace a spatial iPaaS like FME quite yet, but I am being productive with it locally.
The MCP Layer
I wanted the mirror to be usable by AI clients in a first-class way, not just by people writing SQL. That is why the project exposes both REST endpoints and MCP tools.
The MCP layer gives an AI client a constrained vocabulary for interacting with the mirror. Instead of free-form scraping, it gets specific tools like:
- search_places
- search_places_by_geometry
- get_entity
- get_admin_hierarchy
- get_freshness
That makes the access pattern more AI-native. The client is no longer improvising against live public infrastructure. It is working against a bounded local interface designed for the kinds of questions we actually want it to ask.
Larger Questions
This is still a prototype. It uses a static regional extract rather than continuous change feeds. It normalizes only a subset of OSM tags, and it does not settle every licensing, governance, provenance, or sustainability question that follows from AI-scale consumption of open data. It does not address features necessary for scale, such as caching.
But it does show that the technical hurdle is manageable. We can build local mirrors. We can preserve raw source tags. We can carry attribution through every layer. We can expose controlled interfaces through REST and MCP. We can let AI systems query open geospatial data without asking live community infrastructure to absorb every experimental workflow.
The harder question is not whether this can be built. It is how the people building and operating AI systems contribute to the infrastructure they depend on.
By now, we know enough about LLMs to know they share one trait with every computing system that came before them: garbage in leads to garbage out. OpenStreetMap and similar projects provide some of the best available data for many geospatial use cases. If AI systems are going to rely on that data, their builders need to participate in sustaining the patterns that make it usable.
Note: The code for this prototype is available on GitHub. As the presence of “Agents.md” in the repository suggests, Codex was used in the initial generation of the code. The original PRD is also in the repo. There was extensive manual editing after the initial generation. The reader is left to make their own decisions based on this disclosure.
Header image: T.Voekler, CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0, via Wikimedia Commons