I spent the first five years of my career, from 1993 to 1998, doing mostly AML programming. There was also some AutoLISP, MapBasic, Clipper, and Avenue during that time, but it was mostly AML. In hindsight, that was a fortunate place to begin. I had no real exposure to GIS or geography in college, and AML turned out to be a very effective way to build that knowledge. It was not just a programming language I happened to use. It was one of the ways I learned the domain.
Those years were largely focused on production. Early on, that meant data production as I automated and customized workflows for producing Vector Product Format datasets such as VMAP1 and Digital Nautical Chart from hard-copy media. Later, it became cartographic production as I built an AML-based GUI inside ARC/INFO to automate map production for a water utility.
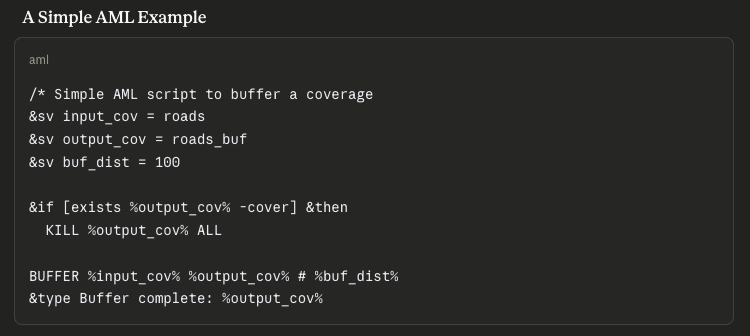
AML was a great way to start precisely because it was a macro language. I was generally automating manual workflows with the same ARC/INFO commands my users were executing themselves. That kept me close to the work in a very practical sense. I was not abstracted away from it by layers of traditional programming constructs. The commands, the workflow, and the user’s understanding of the task were all closely related.
That mattered because it kept me in sync with the people I was supporting. AML helped me understand GIS, but it also enabled my users to mentor me more directly. They could explain the workflow in the language of the system they were already using, and I could translate that into automation without introducing much distance between their intent and my implementation.
Translation Distance
Looking back on that period, one of the things that stands out is how much that closeness shaped the working relationship. Because I was automating the same commands my users were already using, there was very little translation distance between how they described the work and how I represented it in software.
By translation distance, I mean the amount of interpretive space between a user’s description of a task and a developer’s implementation of it. When that distance is short, users can more easily recognize their own process in the automation. They can say, in effect, “Yes, that is what I do,” or “No, that step comes later,” or “You have left out this part.” The conversation stays grounded in the work itself.
That was one of the practical advantages of AML. My users did not have to understand a separate conceptual world in order to guide me. They did not need to think in terms of classes, data models, architectural layers, or abstractions that were invisible to their daily work. They could respond in the language of the workflow, and because the workflow and the automation were so closely related, their corrections were usually precise and useful.
That also made mentorship easier. Since I was still learning GIS, I benefited from being able to learn directly through the operational language of the people doing the work. They were not just telling me what software should do in an abstract sense. They were teaching me how the work itself was performed. In that environment, automation became a way of learning the domain as much as a way of increasing efficiency.
In practical terms, a short translation distance reduced misunderstanding and made iteration more direct. It did not remove the need for judgment, and it certainly did not make the work trivial. But it did mean that users and developers were often looking at the same problem through nearly the same language. That is rarer than it sounds, and it is part of why that experience has been coming back to mind as I work more with AI-assisted coding.
Getting Farther Apart
Part of what made that earlier alignment possible was the nature of ARC/INFO itself. It was primarily a command-line environment. The users I supported were working in commands, sequences, and explicit operations, which meant that the language of their work and the language of my automation were closely connected.
That began to change when ESRI introduced ArcView 2.0. ArcView was fully GUI-driven, and its customization language, Avenue, was object-based. That shift brought real advantages, but it also widened the translation distance. Users now described their workflows in terms of buttons, menus, and interactions on the screen. Anything that went beyond the out-of-the-box behavior was often described in more abstract terms, while I still had to go figure out how to make it real in Avenue.
That changed the relationship in a practical way. My users could no longer offer meaningful feedback on the code itself because the code was no longer legible in any useful sense from within their own workflow. Instead, they had to wait until I had built something they could try. That lengthened the feedback loop and increased the cost of misinterpretation. If I misunderstood something early, it often took longer for both of us to discover it.
That pattern persisted after Avenue. As ArcGIS transitioned to ArcObjects, and ArcObjects in turn could be automated with Visual Basic, C++, .NET, and eventually Python, I was increasingly working in more powerful and more marketable development environments. As a developer, I loved that transition. I was no longer confined to siloed, proprietary scripting languages. I was working in ecosystems with broader value, better tooling, and access to a much wider range of libraries. In many ways, that freedom helped open the door to my eventual move into open-source geospatial work.
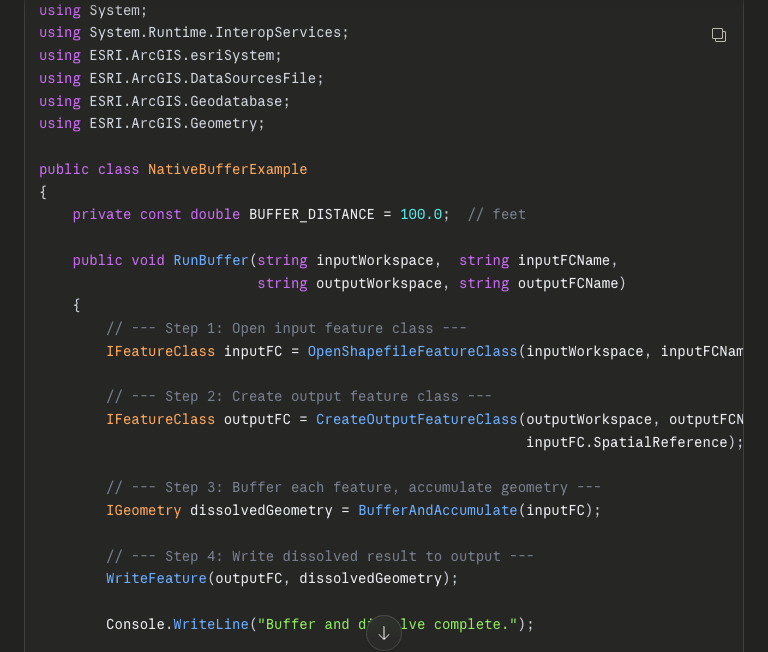
But even as the technical possibilities improved, the abstraction between me and my users kept increasing. The GIS software they used was becoming larger and more complex, and the implementation details were moving farther from the language of their day-to-day work. I could explain those details when needed, but the gap was real. Their eyes would glaze over when I tried to explain the distinction between an IFeatureLayer2 and an IFeatureLayer3. That was not a failure on their part. It was a sign that the translation distance had widened enough that our collaboration increasingly depended on delayed feedback, interpretation, and trust.
Over time, software practice developed its own ways of coping with that widening gap. Agile methods, rapid prototyping, and closer user engagement all helped shorten feedback loops and reduce the cost of misunderstanding. Those were real improvements. But they were still largely process responses to a deeper issue: the language of implementation had moved farther away from the language of the user’s work.
Closing the Gap With AI
What has been interesting to me lately is that AI-assisted coding seems to narrow that distance again, though in a very different way. I am still building with modern languages and frameworks. The code may end up in Python, JavaScript, or somewhere else entirely. But the path into that implementation increasingly begins in language much closer to the way users actually describe their work.
That matters for a reason beyond simple readability. In earlier development models, user-facing artifacts were informative, but not directly actionable. Notes, requirements documents, and process descriptions still had to be translated by a developer into something a machine could use. With AI-assisted coding, natural language itself becomes more operational. Artifacts written in the user’s own nomenclature are no longer just communication tools between user and developer. They can also serve as inputs into implementation.
That changes the feedback loop in an important way. A user can read a prompt or requirements draft and say, “Yes, that is what I mean,” or “No, that is not quite right,” long before I have finished building the thing itself. More importantly, that same artifact can often be used to generate or shape the first version of the implementation. Users are not just reacting to a summary of intent. They are helping refine something that is already actionable.
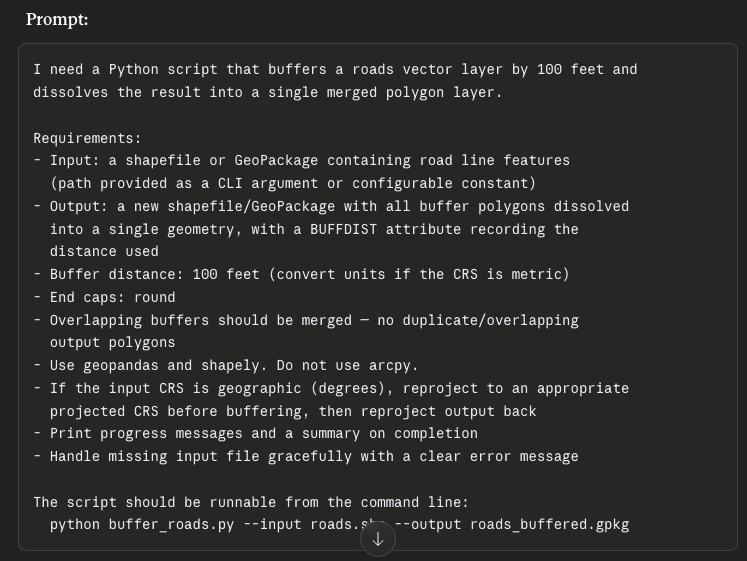
What I find especially notable is that this restores some of the operational value that user language had in the AML years, even though the underlying technology is entirely different. Users can correct the description, refine the terminology, or point out a missing step while the idea is still taking shape, and those corrections can flow more directly into the next iteration. I do not have to give up the power of modern development ecosystems to get some of that earlier closeness back. The final implementation can still live in a general-purpose language with access to contemporary tools and libraries, but the route into that implementation feels less like a hard translation and more like a collaborative refinement of shared intent.
I do not want to overstate that. AI-assisted coding is not a replacement for software judgment. It is a new place to apply it. The translation distance may be shorter between user and developer, but it can widen again between developer and model if the work is handed over too casually.
One-shotting an application with AI can create its own kind of translation distance. The model may produce something plausible, but plausibility is not the same thing as correctness, and it is certainly not the same thing as fidelity to the user’s actual work. The discipline, as I am finding it, is to keep the interaction iterative: shape the artifacts carefully, constrain the task, review what comes back, and validate it against the domain.
That is what has been feeling familiar to me. Not because AI-assisted coding resembles AML technically, and not because it erases the complexity of modern software, but because it seems to restore some of the closeness I remember from those earlier years. The implementation may be very different now. The working relationship, at least in moments, feels less distant.
What I do not mean is that AI-assisted coding is somehow taking us back to AML. The technologies are different, the environments are different, and the scale and complexity of modern software are different. What feels familiar to me is something else. It is a mode of working in which the language of the domain and the language of implementation are brought closer together.
That matters because translation distance is not just a technical issue. It shapes the quality of collaboration. When the distance is short, users can recognize their own work earlier in the process, offer corrections sooner, and help refine intent before too much gets lost in translation. The result is not perfect understanding, but it is often a less lossy path from work as described to work as implemented.
At the same time, I do not see this as reducing the importance of the developer. If anything, it clarifies the role. The developer still does a great deal of development. In my own case, I use AI-assisted coding fairly atomically and still write most of the code myself. Much of the value comes from having a system that can act as a kind of pair programmer, especially since I work alone most of the time. That does not remove my responsibility for framing the problem well, shaping the artifacts that guide the model, constraining the task, reviewing the output, and validating it against the realities of the domain. AI may narrow one kind of translation distance, but it does not eliminate the need for technical judgment.
That, I think, is the pattern I have been noticing. For a long stretch of software development, we gained enormous expressive power at the cost of greater distance between user language and implementation language. AI-assisted coding does not erase that history, but it does seem to offer a partial return to a more closely shared vocabulary. I suspect that reduced translation distance is one of the main reasons AI-assisted coding is resonating so strongly right now. It is not just that people can produce code faster. It is that the path from described work to implemented work feels shorter and more direct. That may be one of the reasons it feels both new and strangely familiar to me.
Header image: Jamie from Birmingham, AL, USA, CC BY 2.0 https://creativecommons.org/licenses/by/2.0, via Wikimedia Commons