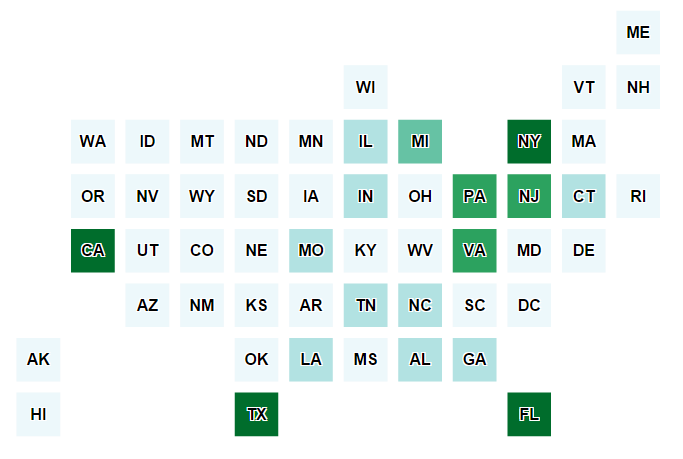
There’s been a lot of attention paid lately to choropleth cartograms using alternate geometries such as squares or hexagons, with good reason. I’m not referring to hex binning per se, although it certainly falls under that umbrella. I am referring to geometric binning such as this, published by the Washington Post:

This visualization appeals to me because it solves the problem of understanding state-level data in the small, clustered Northeastern states while depicting a national view. The arrangement of the squares in a layout reminiscent of the actual geographic placement of the states makes still possible to still glean a regional understanding by glancing at the diagram.
I was drawn to this because I have a customer that sends me monthly, state-level data updates for processing and publication. One of the outputs they want is a map. I have so far found the result unsatisfying precisely because or what I term the “Northeast problem.”
If you follow the link to the image above, you will be taken to a GitHub repository with various R tools to generate similar visualizations. If you are an R user, go there and you will be all set. I, however, have a fairly well-exercised workflow centered around PostGIS, OGR, and occasionally QGIS to generate choropleth maps for display in Leaflet. I didn’t want to port my whole process to R in order to take advantage of the visualization, which is really the last 10% of the workflow. So I decided to build my own fake geometries in PostGIS for the task.
Building the geometries was easy. The actual location of the squares meant nothing, because they weren’t actual geographic features. Putting them in PostGIS was simply a convenience for me so that they would be available for joining with my data at the the end. I have made the geometries available as a GeoJSON file.
Processing the Data
I long ago adopted a best practice of keeping geometries stored in PostGIS with minimal attribution. My database will typically have the US states, for example, with just enough attributes to support joining and labeling. For the states, that means state name, state abbreviation, and FIPS code. Generally, whatever data I am working with for analysis includes the abbrevation or FIPS code, so I can do my analysis and group the results based upon that value. That is all pretty vanilla SQL usually consisting of the appropriate aggregate functions, a GROUP BY clause, and a JOIN. My results always end up as views so that I am never making physical copies of my geometries in my database.
Here is a generic example:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| SELECT | |
| us_states_squares.shape, | |
| us_states_squares.abbr, | |
| us_states_squares.name, | |
| vw_statistics_ytd.ytd | |
| FROM | |
| public.us_states_squares | |
| INNER JOIN public.vw_statistics_ytd ON | |
| us_states_squares.abbr = vw_statistics_ytd.state_abbr | |
| WHERE | |
| vw_statistics_ytd.year = 2015; |
As you can see, I simply join the view to the geometries using the state abbreviation. The view encapsulates whatever my analysis and aggregation may be. In this case, it’s a simple sum grouped by year to come up with a year-to-date total, but it can really contain whatever processing is necessary to get useful state-level data. I will usually put the above SQL into a view also to save myself some typing later
At this point, it’s necessary to explain my workflow. I usually work on the premise of eventually creating static data to serve via a web mapping application. I have found that data doesn’t usually update fast enough to warrant incurring the complexity of specialized map server software or the potential security risk of a live link to a database. So I usually process the data when it is updated and dump the results to a static GeoJSON file for use in my application.
If your data does warrant a live connection and a map server, there may be circumstances where this approach could introduce performance constraints. That would typically be seen when the processing logic is particularly complex but that may again raise questions about the need to connect live to such a process. Such potential issues are beyond the scope of this post, however, so they are not addressed here.
Exporting Static Data
So I now have data processed the way I need it and successfully joined in PostGIS to the geometries I want to use. The next step is to export the data to GeoJSON so I can serve it up to D3. I use OGR for this step, although you can certainly roll more SQL to do that if you are so inclined. The command I use looks like this:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| ogr2ogr -f "GeoJSON" statistics_%2_%1.geojson PG:"host=localhost user=wombat dbname=geo2 password=sufficiently_complex_password" -sql "SELECT * FROM vw_geojson_statistics_ytd WHERE year = 2015" |
Visualizing the Data
Now I want to visualize my data in D3. With my GeoJSON, this is fairly straightforward. The key piece is to get the squares to display properly. Remember that these are fake geometries, placed arbitrarily on the world so that I could keep my GIS-centric workflow intact. We do that in D3 by setting the projection. In this case, it’s a simple equirectangular “projection” (which is actually unprojected). I then use the scale and center properties to orient D3 to my geometries. That can be seen in lines 16 through 19 of the following snippet. The rest is standard D3 map manipulation, which was exactly the point of this exercise. Scroll past the code to see an example of the output.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| d3.json( | |
| "data/statistics.geojson", | |
| function (json) { | |
| //dimensions | |
| var w = 980; | |
| var h = 480; | |
| //get the center of the data | |
| var center = d3.geo.centroid(json); | |
| var svg = d3.select("body").append("svg") | |
| .attr("width", w) | |
| .attr("height", h); | |
| //create the projection used to display the data | |
| //equirectangular for plate carrée in this case | |
| //use scale and center to orient D3 to our arbitrary geometries | |
| var projection = d3.geo.equirectangular() | |
| .scale(2500) | |
| .precision(.77) | |
| .center(center); | |
| //breaks were chosen arbitrarily for this example | |
| var breaks = [20, 15, 10, 5]; | |
| //defines polygon fills for each break | |
| var fills = ['#006d2c','#2ca25f','#66c2a4','#b2e2e2']; | |
| //defines label colors, applying white when polygon fill gets too dark | |
| var textcolors = ['#ffffff','#ffffff','#000000','#000000']; | |
| //create geo.path object, set the projection to merator bring it to the svg-viewport | |
| var path = d3.geo.path() | |
| .projection(projection); | |
| //draw svg lines of the boundries | |
| svg.append("g") | |
| .selectAll("path") | |
| .data(json.features) | |
| .enter() | |
| .append("path") | |
| .attr("d", path) | |
| .style("fill", function(d){ | |
| //applies polygon fills | |
| var ytd = d.properties.ytd; | |
| var retval = "#edf8fb"; | |
| for (i = 0; i < breaks.length; i++) { | |
| if (ytd > breaks[i]){ | |
| retval = fills[i]; | |
| break; | |
| } | |
| } | |
| return retval; | |
| }); | |
| //label the squares with state abbreviations | |
| svg.selectAll(".subunit-label") //this is a style defined elsewhere | |
| .data(json.features) | |
| .enter().append("text") | |
| .attr("class", function(d) { return "subunit-label " + d.id; }) | |
| .attr("transform", function(d) { return "translate(" + path.centroid(d) + ")"; }) | |
| .attr("dy", ".35em") | |
| .text(function(d) { return d.properties.abbr; }); | |
| }); |
nice one, Bill 🙂
Thanks, Paolo. I hope all is well on your end. 🙂